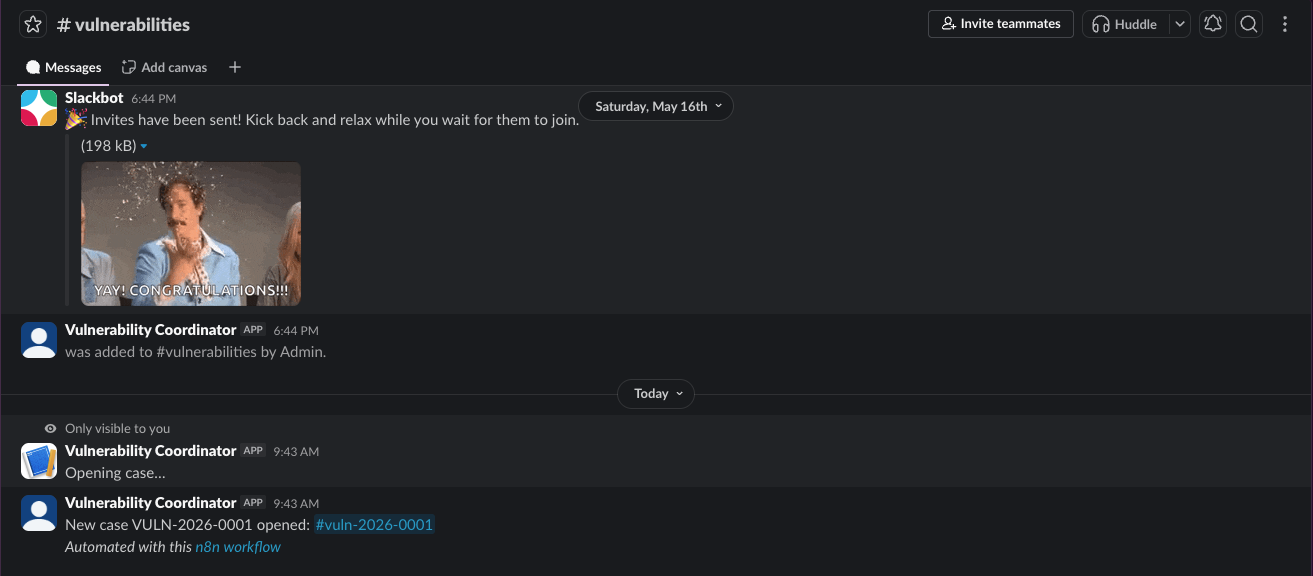
There is a particular feeling that I think anyone who has done vulnerability management at any kind of scale will recognise.
A finding, a potential vulnerability, has just come in. You know which tool detected it, you know roughly which team owns the affected component, you know there is a process somewhere that defines what is supposed to happen next. But the actual work in the next ten minutes is this: you open six browser tabs, ask in two Slack channels, hunt for the ticket from last quarter that resembled this one, decide whether the SLO clock has already started ticking, decide whether this is going to need a CVE, decide whether anyone outside the security team needs to be told. None of that work is technical. All of it is coordination.
This is not a tooling gap. There are dozens of vulnerability management platforms, most of which are perfectly competent at what they do. It is not a people gap either - the engineers I have worked with on this kind of thing are smart and motivated. It is a process integration gap, which is a specific kind of problem that no individual vendor can solve for you, because the integration only exists at the seams between the things you already own.
I built a small system over a few evenings to test an idea: that the boring parts of vulnerability handling - the audit trail, the consistent state, the handoffs between people - can be solved with surprisingly little code, on free-tier infrastructure, if the architecture is the right shape. Let me walk you through what came out of that, because I think the shape is worth more than the implementation.
Disclaimer: I do want to highlight that running something like this in production requires more than the features that are shipped in most free tier SaaS, but it can get you an idea of what it would look like.
The state machine is the program
The thing that took me longest to internalise, despite having read about state machines for years, is that you can build a workflow tool by writing the state machine first and then asking what scaffolding is needed around it. Most automation projects start the other way around: someone builds a UI, or a custom backend, or a Slack bot, and the state machine ends up implicit - scattered across event handlers, database fields, and what some Slack thread agreed on three months ago.
The inversion worth dwelling on is this. When the state machine lives in the database, with state transitions enforced by a function that refuses bad transitions and writes a row to a transition log on every legal one, you do not need most of the surrounding software you would otherwise have built. You do not need a UI that knows what state things are in. You do not need orchestration code that decides what happens next. You need three thin layers around the state machine: one that lets people interact with it, one that handles the events those interactions generate, and one that lets you see the shape of the whole thing. Everything else is a database row.
Four layers, one job each
The architecture, drawn at the lowest possible resolution, is four layers stacked on top of a single Postgres database.
- Postgres holds the state machine and the source of truth. State transitions happen through a
transition_vuln function that refuses illegal transitions and writes a row to state_transitions on every legal one. The audit trail is not bolted on; it is a side effect of state changes.
- n8n is the orchestration layer. It listens for events (a slash command, a button click, a webhook), parses them, calls
transition_vuln or some other parameterised query, and posts the result back to wherever it came from. n8n never makes decisions; it routes them.
- Slack is the interaction layer. Slash commands and Block Kit buttons are how humans tell the state machine what they want to happen. Slack stores nothing of substance. If a case channel disappeared tomorrow, no information would be lost.
- Grafana is the observability layer. It reads directly from the same Postgres database that the workflow writes to. There is no ETL. The dashboard panels are SQL queries against the same rows that drive the workflow.
The LLM (Claude Opus, in this case) sits alongside this stack rather than inside it. n8n invokes the LLM once per case, at a specific stage, to generate three drafts. The LLM never advances the lifecycle. It never publishes anything. It produces text and then it stops.
If you take only one thing away from this post, take this: each of those layers has exactly one job. Slack never stores state. n8n never makes decisions. The LLM never advances the lifecycle. The discipline of those separations is the entire reason the system stays small.
 The intake workflow in n8n: one webhook, and a vulnerability case is born. The graph itself is the architecture.
The intake workflow in n8n: one webhook, and a vulnerability case is born. The graph itself is the architecture.
One case, cradle to grave
Let me walk a single fictional vulnerability through the system, because the architecture only earns its keep in practice.
A reporter (internal or external) believes they have found a problem. The summary is JWT alg:none accepted by auth service. Somebody on the security team types a single slash command into Slack.
/vuln-new JWT alg:none accepted by auth service
 The whole interaction starts with a single slash command. Everything that follows cascades from this deliberate human action.
The whole interaction starts with a single slash command. Everything that follows cascades from this deliberate human action.
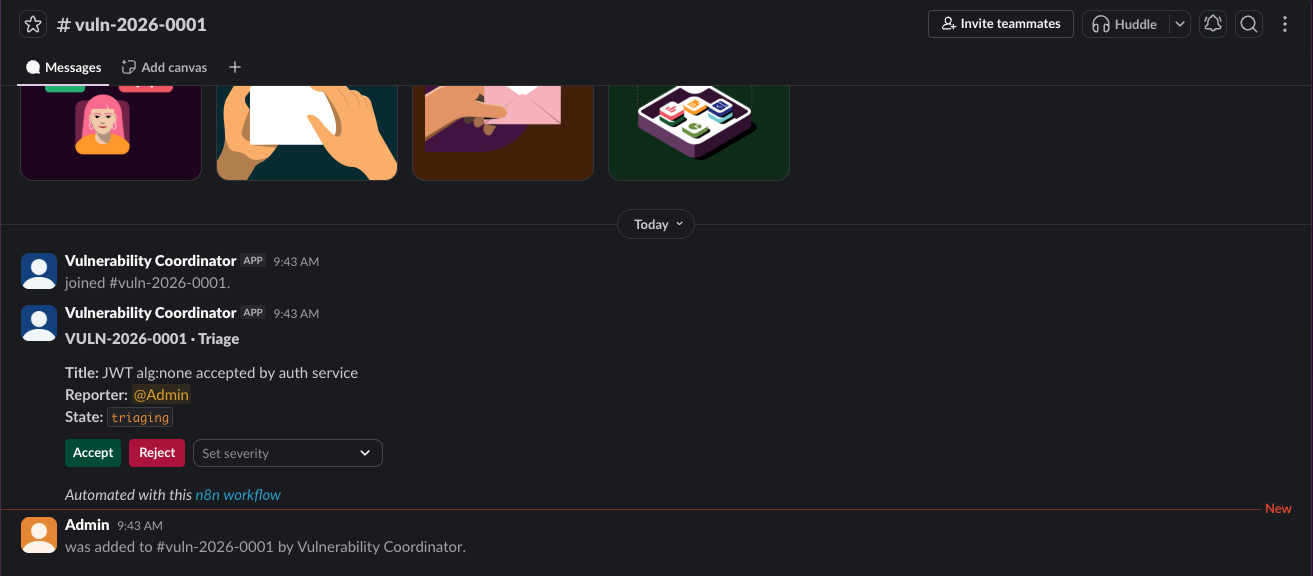
Behind the scenes, this fires a webhook into n8n. The intake workflow runs in something like three seconds. It generates a case identifier (VULN-2026-0001), inserts a row into vulnerabilities with state triaging, creates a per-case Slack channel (#vuln-2026-0001), invites the person who invoked the /vuln-new command into it, posts a triage card with the current state and the legal next actions, and writes an entry to the audit log. One webhook, a few n8n nodes and one human action.
 Each case gets its own channel. The card surfaces the current state and the legal next actions - nothing more.
Each case gets its own channel. The card surfaces the current state and the legal next actions - nothing more.
The channel-per-case pattern is one of those decisions that sounds extravagant until you have lived with the alternative. When every case has its own channel, the conversations stay with the artefact. There is no archaeology required six months later to figure out who said what about which finding. The channel name is the case identifier. The pinned message is the latest state. The history is the history.
And every node in that intake workflow leaves a forensic trail. n8n records each execution with full input and output for every node, so when something does break (and something always does break) the first place I look is the execution log.
 n8n’s execution log gives full per-node observability. When something breaks at 02:00, this is where you start.
n8n’s execution log gives full per-node observability. When something breaks at 02:00, this is where you start.
This matters because the most common dismissal of no-code tools is that they cannot be debugged. That dismissal is a category error. n8n is not “no-code”; it is a workflow runtime with a visual editor. The Code nodes carry real JavaScript. The Postgres nodes run parameterised SQL. What the visual editor buys you is legibility - someone new to the team can open n8n, look at the Switch node, and immediately understand what the system does, without first reading 800 lines of Express middleware.
Triage
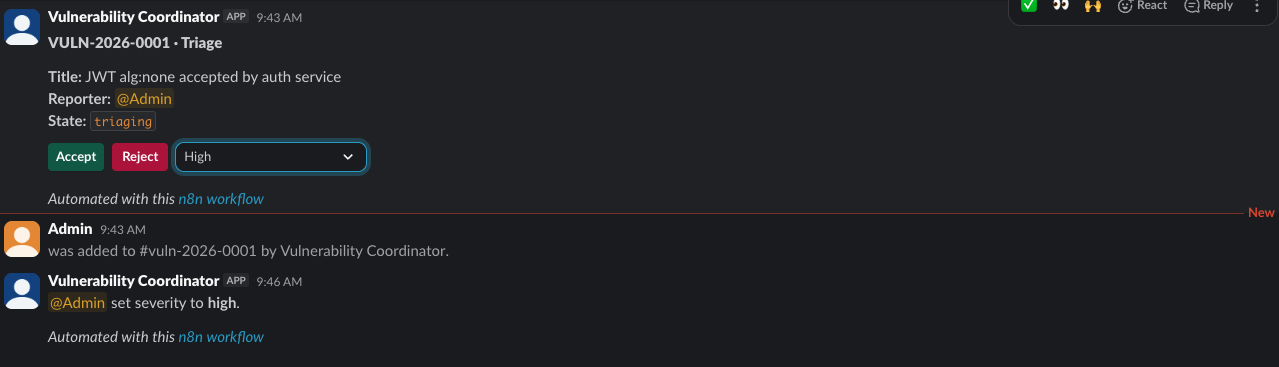
The triage card has three controls: accept, reject, and a severity dropdown. Clicking severity is the simplest case to explain - it is a column update, not a state transition. But it still flows through the orchestration layer in exactly the same shape as everything else.
 Even a simple field update flows through the orchestration layer. Consistency over cleverness.
Even a simple field update flows through the orchestration layer. Consistency over cleverness.
A button click fires an event to n8n’s interactivity webhook. n8n parses the action, branches on the action identifier through a Switch node, calls the appropriate parameterised query, and replies into the channel. The whole round trip is about half a second.
If you want proof that the database is the source of truth, you can go look at it directly.
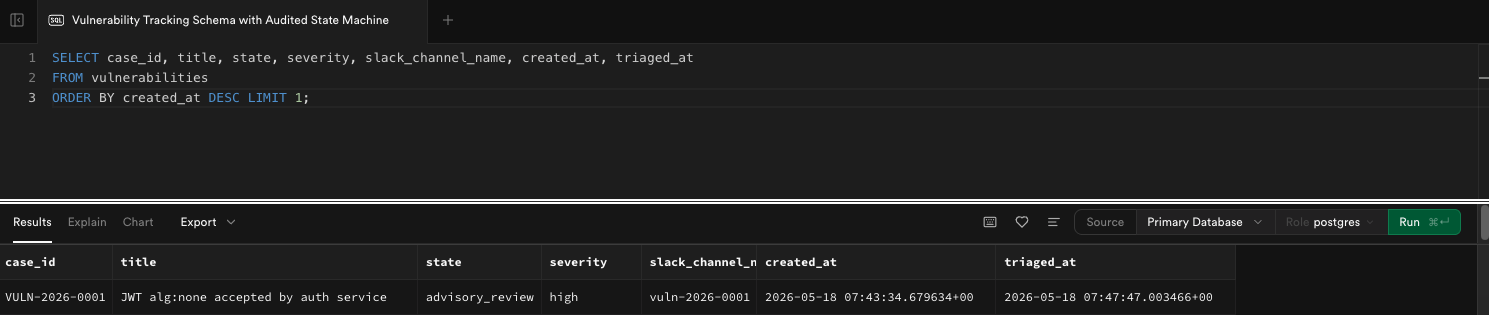 Postgres is the source of truth. Every Slack interaction has a corresponding row.
Postgres is the source of truth. Every Slack interaction has a corresponding row.
State transitions
Now the case moves. Someone clicks Accept, which transitions the state from triaging to accepted. Then Mark in remediation, which moves it to in_remediation. Once remediation is done, all that is needed is to press Mark remediated, which moves it to remediated. Three button clicks, three state transitions, three new rows in state_transitions, three confirmation breadcrumbs in the channel.
 The lifecycle visualised: three button clicks, three rows in
The lifecycle visualised: three button clicks, three rows in state_transitions, three confirmation messages. The lifecycle is the audit trail.
This is the moment where the state machine pattern earns its keep. Every transition is enforced. Try to mark something remediated that was never accepted, and transition_vuln refuses. Try to publish an advisory for a case that is still in triage - same answer. The illegal paths are simply not reachable from the UI, because the UI is generated from the legal-next-actions list, which is generated from the state machine.
All of this routing is mediated by one Switch node in the interactivity workflow. Every button on every triage card, every dropdown selection, every approval click - they all enter the workflow at the same place, get routed by action identifier, and exit through the appropriate Postgres node.
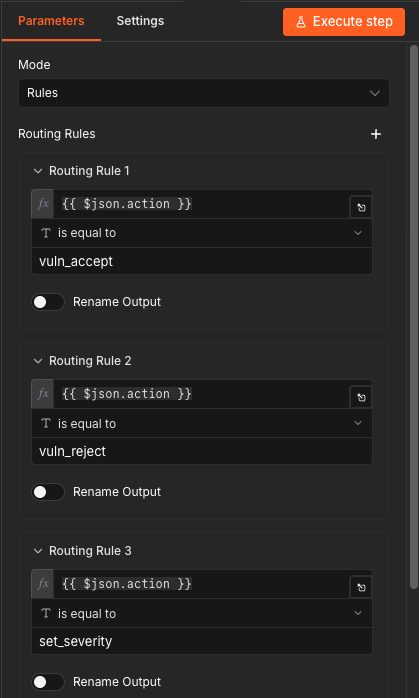 One Switch node, every interactive event. The state machine made visible.
One Switch node, every interactive event. The state machine made visible.
Enrichment
Severity is one field. A full vulnerability record needs more than that: a CVSS score and vector, a CVE identifier, an affected component, affected versions, fixed versions, a description. These are not state transitions; they are data enrichment. They get their own slash command.
/vuln-update cvss:7.5 cvss-vector:"CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:U/C:H/I:N/A:N" cve:CVE-2026-9001 component:"auth-service" affected:"1.0.0 - 1.4.7" fixed:"1.4.8" description:"The auth service accepts JWTs with the 'alg' header set to 'none', bypassing signature verification entirely."
 Structured data enrichment without leaving Slack. The slash command is the form.
Structured data enrichment without leaving Slack. The slash command is the form.
Inside the case channel, you type a single line with key:value pairs (/vuln-update cvss:7.5 cve:CVE-2026-9001 component:"auth-service"...), n8n parses it, validates the keys against a whitelist of allowed columns, and runs a single parameterised UPDATE. The reply confirms exactly which fields changed. No web forms, no separate tickets, no copy-paste between tools.
This is where the inversion I mentioned earlier really lands. The slash command is the form. The Slack channel is the ticket. The state machine is the workflow. There is no separate system that needs to stay in sync with another system.
Advisory generation
Here is where the LLM enters. A button on the triage card says “Generate advisory”. Clicking it fires the advisory generation workflow in n8n. That workflow reads the full case record from Postgres, assembles a structured prompt with the technical details, calls Anthropic’s API once, gets back JSON with three drafts (a security advisory, an executive summary, a customer disclosure), stores them in advisory_artifacts, and posts them back into the case channel.
 The LLM is one node out of many. It produces text. n8n stores it, posts it, and gives humans the final word.
The LLM is one node out of many. It produces text. n8n stores it, posts it, and gives humans the final word.
The thing I want to dwell on is what the LLM is not doing here. It is not deciding what state the case is in. It is not advancing the lifecycle. It is not publishing anything. It is being handed a structured set of facts and asked to produce three pieces of text, each tailored to a different audience.
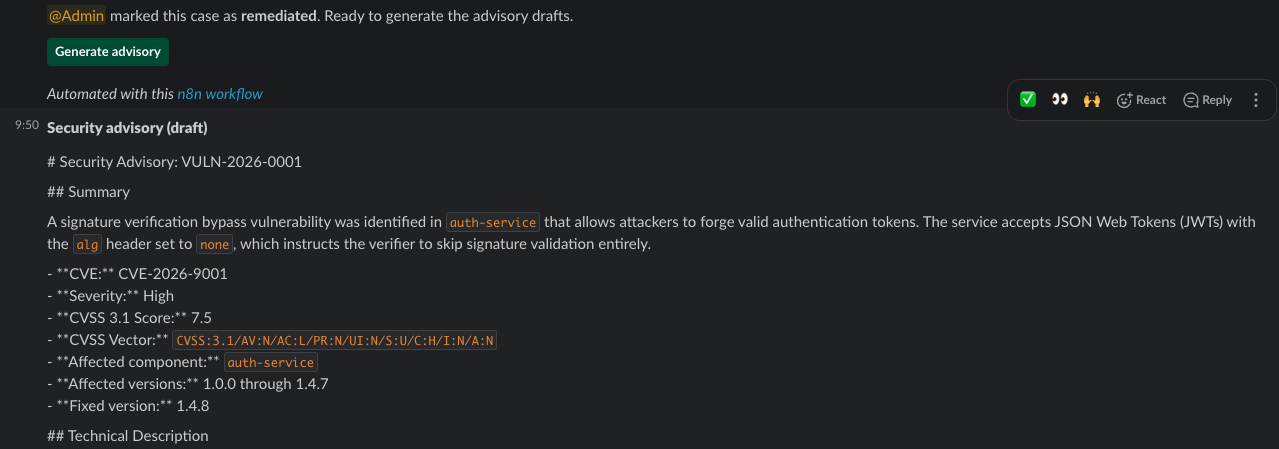 Three drafts for three audiences. Human approval is a button, not a configuration setting.
Three drafts for three audiences. Human approval is a button, not a configuration setting.
The drafts arrive in the channel with explicit (draft) labels. The security advisory has two buttons next to it: Approve & publish, and Regenerate. Nothing has been published. Nothing will be published until a human clicks the button. That separation - LLM produces content, humans approve content, state machine records the decision - is what makes the system trustworthy by construction.
I am going to keep banging this drum, because I think it is the part of the design that matters most. AI will make a good security program great and a poor security program useless. The way you stay on the good side of that line is to be deliberate about which decisions are LLM decisions and which are human decisions. In this system, no LLM call advances state. Period.
Status and audit
At any point in the lifecycle, you can run /vuln-status and get an ephemeral message (visible only to you) that dumps the full case record: technical details, ownership, disclosure timeline, lifecycle timestamps, every state transition, every audit event, every advisory artefact. One slash command, one ephemeral message, the entire history of the case.
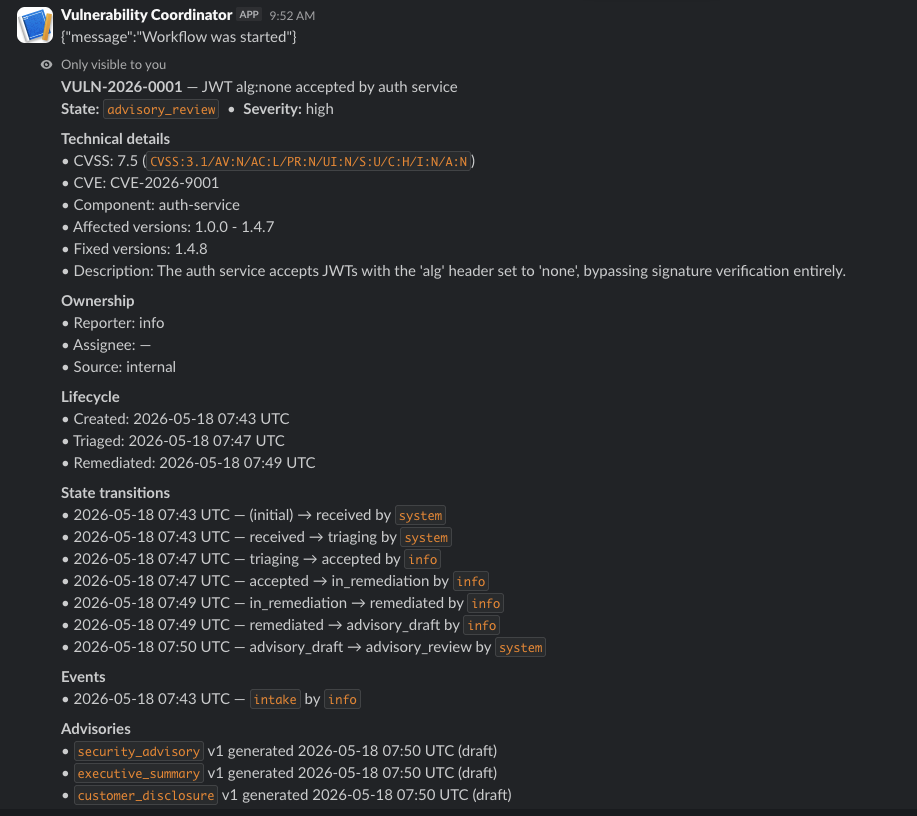 Every decision, every transition, every actor - recoverable from Postgres in one query. Compliance evidence is a side effect.
Every decision, every transition, every actor - recoverable from Postgres in one query. Compliance evidence is a side effect.
I want to be careful not to oversell this, but there have been few cases when I’ve worked in an environment where compliance evidence was actually a free side effect of doing the work. The default is to do the work, get to the end, and then go back and try to reconstruct it from Slack threads and people’s memories. This pattern inverts that. The work is the evidence.
Publish
Final step. Someone clicks Approve & publish on the security advisory. The case transitions to published. The advisory broadcasts into the parent #vulnerabilities channel for visibility. The audit log gets a publish entry. The case channel stays around for archival.
Observability you do not have to build
The Grafana dashboard reads directly from the same Postgres database that the workflow writes to. State distribution, intake rate, MTTR by severity, embargo watch, lifecycle funnel, recent transitions - all of it is plain SQL against the production rows.
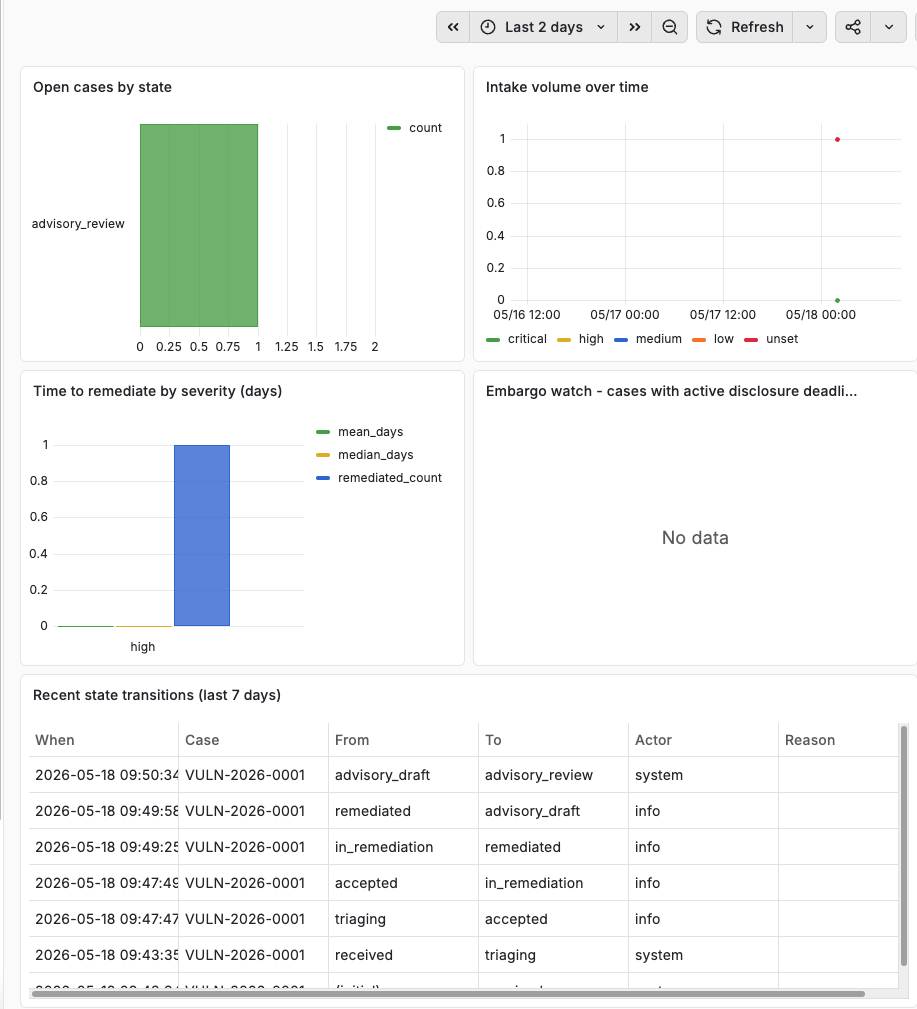 Grafana reads directly from Postgres. The same rows that drive the workflow drive the dashboard.
Grafana reads directly from Postgres. The same rows that drive the workflow drive the dashboard.
This is the part I find quietly exciting. In most environments, getting operational visibility into a workflow tool means standing up a separate analytics pipeline: extract from the workflow tool, transform, load into a warehouse, build dashboards on top. Here, the warehouse and the workflow are the same database. There is no skew between what the workflow sees and what the dashboard sees, because they are reading the same rows.
A short word on n8n itself
It is worth being specific about why n8n earns its place in this stack, because “no-code automation tool” is a phrase that does it no favours.
n8n is deterministic glue, not a code replacement. The three workflows in this build (intake, interactivity, advisory generation) each handle real work: webhook parsing, conditional routing through a Switch node, parameterised SQL against a production-grade database, calls to the Anthropic API, multi-step Slack interactions assembled from Block Kit. The Code nodes carry actual JavaScript. None of this is point-and-click magic; it is a workflow runtime with a visual editor.
The visual editor pays for itself in legibility. When a state machine spans multiple Slack interactions and multiple database tables, seeing the flow as a graph is genuinely useful. Onboarding someone new to the system is “open these three workflows and look at the Switch node,” not “read this codebase.”
The whole thing is event-driven rather than batch. Every state change is triggered by a real-time event: a slash command, a button click, a transition firing the next step. There is no polling, no cron job sweeping for “things that need to happen.” This matters because vulnerability handling is inherently event-driven. You do not know when a report will arrive, and you do not want it sitting in a queue.
And the three workflows all follow the same shape: webhook (or trigger) -> parse -> branch -> mutate database -> respond. Once you have read one, you have read the others. That consistency is what keeps the system small and learnable.
Caveats in the PoC
I do not want to leave the impression that this was effortless. It was not. A few honest notes on the rough edges, because I think it is more useful to name them than to pretend they did not exist.
The slash command parser is hand-written and modestly fragile around quoting. CVSS vectors with embedded slashes and colons are exactly the values that stress a key:value parser. I ended up with a tokenizer that handles quoted strings and balanced brackets, but I would not point at it and call it elegant.
The cards in Slack stays the same, even after the state has been transitioned - making it possible to call the same transition again, which would fail in n8n due to constraints in Postgres. There could be a lot of error handling around this in n8n that displays useful messages back to the slack user, but for now - I just designed the flow for intended usage, nothing else.
The trial version of n8n lacks some of the features that you would really want for this kind of project, so in the current form - it would not work in any other situation than a PoC, to show what could be done with fairly low effort - while operating in familiar tools.
None of those are fatal, and the shape of the system is what generalises. The exact set of papercuts depends on which version of which tool is shipping when you read this.
What this costs
Slack: free, on the workspace plan I already had. Supabase: free, well under any of the limits. Grafana Cloud: free. n8n: trial during the build, then either €20-€25/month for the managed cloud tier or free if you self-host the Community Edition. Anthropic: roughly two to five cents per advisory generation, depending on the model and the size of the case context. Total spend across the few evenings the build took was under five dollars, almost all of which went to Anthropic.
I mention this not because it is a marketing point but because it changes who can build something like this. The argument against home-grown automation has historically been infrastructure cost and operational overhead. With managed Postgres, managed orchestration, managed dashboards, and pay-per-token LLMs, the infrastructure cost goes to roughly zero and the operational overhead goes to “remember to check the dashboard occasionally.” That is a different conversation than the one we were having ten years ago.
What changes, what stays the same
The architecture is the lesson. The implementation is replaceable. What matters is the strict separation: an authoritative state machine in Postgres, an event-driven orchestrator that turns chat interactions into state transitions, a chat-native interaction layer that never holds state of its own, and an LLM constrained to content generation behind a human approval gate. Each of those layers has one job. The discipline of one-job-per-layer is what keeps the system small enough to fit in your head, and trustworthy enough to actually use.
This started as “what if I built a tiny vulnerability tool in a few evenings.” It ended up as a small, opinionated demonstration that the boring parts of security work - the coordination, the audit trail, the consistent state - can be solved with surprisingly little code, if the architecture is right.
Are the integrations always elegant? No. Does the LLM occasionally produce a draft that needs a heavy edit? Yes. Will you discover edge cases in the state machine the moment a real human starts using it? Almost certainly. None of that bothers me. What does bother me is when systems get the architecture wrong and try to paper over it with more code, more tools, more vendors. The architecture is the cheap part to get right. Everything downstream gets more expensive when you get it wrong.
